Unsecured Souls Trapped: Navigating The Deadlock Labyrinth
In the intricate dance of digital systems, where countless processes and threads vie for attention and resources, a silent, insidious threat often lurks: the dreaded deadlock. This isn't merely a technical glitch; it's a profound paralysis, a state where "unsecured souls"—be they critical data, essential processes, or even the very trust of users—become irrevocably trapped, unable to move forward. Understanding this digital quagmire is paramount, not just for developers and system administrators, but for anyone who relies on the seamless operation of modern technology.
The concept of deadlock, while rooted in computer science, extends its chilling implications far beyond lines of code. It speaks to a fundamental vulnerability in complex, interconnected systems, where a seemingly minor contention can cascade into a complete system freeze. For our "unsecured souls," this means data held hostage, services rendered inaccessible, and the potential for significant financial or operational losses. Delving into the mechanics of deadlock, its causes, detection, and most importantly, its prevention, is crucial for safeguarding the digital landscape we increasingly depend upon.
Table of Contents
- Understanding the Core: What is a Deadlock?
- The Classic Deadlock Scenario: A Digital Tug-of-War
- Beyond Threads: Where Deadlock Haunts "Unsecured Souls"
- The Peril of Asynchronous Operations and Hidden Deadlocks
- Detecting the Digital Paralysis: Signs and Symptoms
- Fortifying Your Digital Defenses: Preventing Deadlock
- Recovering from the Abyss: Strategies for Deadlock Resolution
- The Ethical Dimension: Preventing "Unsecured Souls" in AI and Automated Systems
Understanding the Core: What is a Deadlock?
At its most fundamental level, a deadlock is a state of a system in which no single process/thread is capable of executing an action. Imagine two cars approaching a single-lane bridge from opposite directions. Both want to cross, but only one can go at a time. If both cars decide to enter the bridge simultaneously, neither can proceed, and both are stuck. This is the essence of a deadlock in the digital realm. As mentioned by others, a deadlock is typically the result of a situation where multiple processes or threads are competing for a limited set of resources.
In the context of computing, these "resources" can be incredibly varied. They might include access to a specific memory location, a database record, a file, a network connection, or even a peripheral device like a printer. When two or more threads or processes require exclusive access to such resources to complete their tasks, and they acquire them in a specific, unfortunate sequence, a deadlock becomes inevitable. The system grinds to a halt, processes hang indefinitely, and the "unsecured souls" of data and functionality are left in limbo.
The Anatomy of a Digital Stalemate
For a true deadlock to occur, four specific conditions, often referred to as the Coffman conditions, must simultaneously be met. Understanding these is key to both identifying and preventing the digital paralysis that can trap unsecured souls:
- Mutual Exclusion: At least one resource must be held in a non-sharable mode. Only one process at a time can use the resource. If another process requests that resource, the requesting process must be delayed until the resource has been released. This is often the case when processes are trying to get exclusive access to devices, files, locks, servers, or other resources.
- Hold and Wait: A process must be holding at least one resource and waiting to acquire additional resources that are currently being held by other processes.
- No Preemption: Resources cannot be forcibly taken from a process holding them. They must be released voluntarily by the process after it has completed its task.
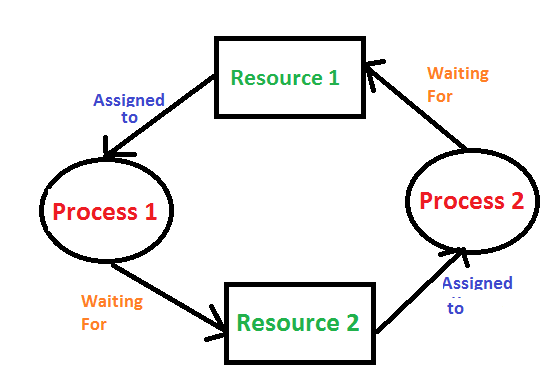
- Circular Wait: A set of processes (P0, P1, P2, ..., Pn) must exist such that P0 is waiting for a resource held by P1, P1 is waiting for a resource held by P2, ..., Pn-1 is waiting for a resource held by Pn, and Pn is waiting for a resource held by P0. This circular dependency is the ultimate trap for unsecured souls.
If any one of these conditions is not met, a deadlock cannot occur. Therefore, strategies for preventing deadlocks often involve breaking one or more of these conditions.
The Classic Deadlock Scenario: A Digital Tug-of-War
To truly grasp the insidious nature of deadlock, let's consider the classic scenario, a simplified yet powerful illustration of how threads can become hopelessly intertwined. This often has something to do with threads trying to acquire shared resources. Imagine two threads, Thread A and Thread B, and two resources, Resource X and Resource Y. The classic deadlock scenario is where Thread A is holding lock X and wants to acquire lock Y, while Thread B is holding lock Y and wants to acquire lock X.
Here’s how the tragic sequence unfolds:
- Thread A acquires a lock on Resource X.
- Thread B acquires a lock on Resource Y.
- Now, Thread A attempts to acquire a lock on Resource Y, but it's held by Thread B. So, Thread A waits.
- Simultaneously, Thread B attempts to acquire a lock on Resource X, but it's held by Thread A. So, Thread B waits.
Since neither can complete what they are trying to do, both threads are indefinitely blocked. They are in a perpetual waiting game, each holding onto what the other needs, and neither willing or able to release their current hold. This is a program that purposely causes deadlock between two threads that are both trying to acquire locks for the same two resources, demonstrating the core problem. The system becomes unresponsive, and any data or operations tied to these threads become effectively frozen, akin to unsecured souls caught in a digital purgatory.
Beyond Threads: Where Deadlock Haunts "Unsecured Souls"
While the classic examples often involve threads and locks in software, the concept of deadlock extends far beyond. Occurs when processes are trying to get exclusive access to devices, files, locks, servers, or other resources. In resource deadlock model, a process can be waiting for any number of resources. The "unsecured souls" in this broader context are not just abstract processes, but tangible entities: user data, critical business operations, security mechanisms, and even the very trust users place in a system.
Consider a large-scale database system. If two different applications (processes) simultaneously attempt to update the same two records, but in a conflicting order, a database deadlock can occur. One application might lock Record A and then try to lock Record B, while the other locks Record B and then tries to lock Record A. The result? Both transactions hang, potentially leading to data corruption, lost updates, or a complete system slowdown. The "unsecured souls" here are the integrity of the data and the continuity of business operations.
Even in distributed systems, where services communicate across networks, deadlocks can emerge. Imagine a microservices architecture where Service A calls Service B, which in turn calls Service C, and Service C then tries to call Service A to complete a request. If each service holds a resource (e.g., a network connection, a processing slot) while waiting for the next, a distributed deadlock can paralyze the entire chain of operations. This impacts user experience directly, leaving users with "unsecured souls" in the form of pending transactions or inaccessible services.
Data Integrity in Peril: The Unseen Cost of Resource Contention
The implications of deadlock, particularly for data integrity, are profound and often underestimated. When a transaction or process is caught in a deadlock, it cannot complete its work. This means that any partial changes it might have made are left in an inconsistent state, or it cannot commit its intended changes. If not handled properly, this can lead to corrupted data, lost information, or a database that no longer accurately reflects the real world. For example, if a banking transaction involving two accounts gets deadlocked, funds might be debited from one account but never credited to the other, leaving the financial "souls" of the users in an unsecured and precarious state.
Beyond direct data corruption, deadlocks consume valuable system resources. Threads or processes caught in a deadlock continue to occupy memory, CPU cycles, and locks, preventing other legitimate operations from proceeding. This resource exhaustion can lead to a cascading failure, where even unrelated parts of the system slow down or become unresponsive, amplifying the impact on all "unsecured souls" within the system.
The Peril of Asynchronous Operations and Hidden Deadlocks
In modern software development, asynchronous programming has become a cornerstone, particularly for building responsive user interfaces and scalable network applications. Concepts like `async/await` allow programs to perform long-running operations without blocking the main thread, making applications feel more fluid. However, as I've explored on my blog, blocking in asynchronous code causes deadlock in subtle and often hard-to-diagnose ways.
The promise of `await` is that it will asynchronously wait until the task completes, freeing up the current thread to do other work. But if an asynchronous method calls a synchronous method that then blocks on a resource, and that resource is being held by another thread that is waiting for the original asynchronous method to complete, you've created a classic deadlock. For example, if threads t1 is waiting for a lock that t2 holds, and t2 is waiting for t1 to complete its asynchronous operation, you have a circular dependency that `async/await` alone cannot resolve.
This type of deadlock is particularly insidious because it doesn't manifest as an obvious "stuck" thread in the debugger. Instead, the application might simply become unresponsive, or certain operations might never complete, leaving users with the feeling that their "unsecured souls" (their data, their commands) are lost in the digital ether. Developers must be acutely aware of how synchronous blocking calls interact with asynchronous contexts to avoid these hidden traps.
Detecting the Digital Paralysis: Signs and Symptoms
Detecting a deadlock is often the first step towards resolution, but it's not always straightforward. The most obvious sign is a system that simply stops responding or a specific application that hangs indefinitely. Users might report "spinning wheels," unresponsive buttons, or transactions that never complete. On the backend, system administrators might observe processes consuming CPU but not making progress, or an increasing number of blocked threads in monitoring tools. Deadlock detected while waiting for resource is a common message in logs, indicating that the system's internal mechanisms have identified a problem.
Many modern database systems, like Oracle, have sophisticated internal mechanisms for deadlock detection. When a deadlock is detected while waiting for a resource, the system often automatically rolls back one of the transactions involved in the deadlock. This is a crucial recovery mechanism, as it breaks the circular wait condition and allows the other transaction to proceed. While this causes one transaction to fail, it prevents the entire system from grinding to a halt. It would be a good idea to monitor for such messages and have robust error handling in place for applications that might experience rollbacks due to deadlocks.
The Oracle's Wisdom: Automated Deadlock Resolution
Database management systems (DBMS) are particularly vulnerable to deadlocks due to their heavy reliance on locking mechanisms to ensure data consistency. Recognizing this, many sophisticated DBMS, such as Oracle, incorporate advanced deadlock detection and resolution algorithms. When a deadlock is detected while waiting for resource, and rolls back one of the transactions involved in the deadlock which Oracle specifically identifies, it's a testament to the system's self-preservation capabilities. Oracle's approach typically involves choosing a "victim" transaction—often the one that has done the least work or has the fewest locks—and automatically rolling it back. This action releases the locks held by the victim, thereby breaking the deadlock and allowing the remaining transactions to complete. While this results in an error for the "victim" transaction, it prevents a catastrophic system-wide freeze, safeguarding the majority of "unsecured souls" (data and operations) from complete paralysis. This automated intervention is a critical layer of defense, but it also highlights the importance of designing applications to gracefully handle transaction failures and retries.
Fortifying Your Digital Defenses: Preventing Deadlock
The best strategy for dealing with deadlocks is to prevent them from occurring in the first place. This requires careful design and adherence to specific principles. To avoid this sort of deadlock when locking, developers and architects can employ several techniques:
- Resource Ordering: The most common and effective prevention strategy. Establish a global ordering of resources and ensure that all processes acquire resources in that strict order. For example, if processes always acquire Resource A before Resource B, a circular wait cannot form. This simple rule can save countless "unsecured souls" from digital paralysis.
- Lock Timeout: Implement timeouts for lock acquisition. If a thread tries to acquire a lock and waits for too long, it can abort the attempt and release any locks it currently holds. This breaks the "hold and wait" condition, though it requires the application to handle the failed acquisition gracefully (e.g., retrying the operation).
- Deadlock Avoidance (e.g., Banker's Algorithm): More complex algorithms that dynamically decide if a resource request can be granted without leading to a deadlock. These require knowing the maximum resource needs of each process in advance and are often used in operating systems.
- Breaking Mutual Exclusion: While often impossible for critical resources, sometimes resources can be designed to be shareable (e.g., read-only access), reducing the need for exclusive locks.
- Preemption: Design systems where resources can be forcibly taken from a process. This is complex and often undesirable for data consistency but can be a last resort.
- Careful Asynchronous Design: As mentioned, avoid mixing synchronous blocking calls with asynchronous contexts. Ensure that asynchronous operations do not inadvertently block threads that are needed to complete other operations they depend on.
Proactive design, rather than reactive troubleshooting, is the key to protecting "unsecured souls" from the digital paralysis of deadlock.
Recovering from the Abyss: Strategies for Deadlock Resolution
Even with the best prevention strategies, deadlocks can occasionally slip through, especially in highly complex or dynamic systems. When a deadlock does occur, the system needs a way to recover. In case of a deadlock, the primary goal is to break the circular wait and allow processes to continue. Common recovery strategies include:
- Process Termination: The simplest but most brutal approach. Terminate one or more processes involved in the deadlock. This breaks the cycle, but the terminated processes lose all their work. The challenge is choosing which process to terminate to minimize the impact on "unsecured souls" (data, user experience).
- Resource Preemption: Forcibly take resources from one or more processes involved in the deadlock and allocate them to others. This requires the ability to save and restore the state of the process that loses its resources, which can be complex.
- Rollback: Roll back one or more processes to an earlier, safe state where they did not hold the resources causing the deadlock. This is a common strategy in database systems, where a transaction can be rolled back to its beginning or to a specific savepoint. Deadlock detected while waiting for resource, and rolls back one of the transactions involved in the deadlock, which is a prime example of this strategy in action. While it means losing some work, it's often preferable to a complete system freeze.
Effective recovery mechanisms are vital for system resilience. They act as a safety net, ensuring that even if "unsecured souls" get momentarily trapped, there's a clear path to release them and restore system functionality, albeit with potential data loss or operational setbacks for the affected processes.
The Ethical Dimension: Preventing "Unsecured Souls" in AI and Automated Systems
As we increasingly rely on artificial intelligence, autonomous agents, and highly automated systems, the concept of deadlock takes on an even more profound, almost ethical, dimension. Imagine a scenario where two AI-driven systems, perhaps managing critical infrastructure or financial markets, enter a state of deadlock over shared control or data access. Since neither can complete what they are designed to do, the consequences could be catastrophic, far beyond a mere software bug. The "unsecured souls" here could be human lives, economic stability, or even the very fabric of societal trust in technology.
Preventing deadlocks in such critical AI and automated systems moves from a technical challenge to an ethical imperative. It requires not only robust software engineering practices but also careful consideration of how these systems interact, prioritize, and resolve conflicts. Designing for graceful degradation, implementing failsafe mechanisms, and ensuring transparency in decision-making processes become paramount. This way you can have something in place to be able to troubleshoot any deadlock, and critically, understand its impact on human stakeholders. The responsibility lies with developers and policymakers to ensure that the complex interdependencies of future systems do not create inescapable traps for the "unsecured souls" they are designed to serve and protect.
Conclusion
The journey through the labyrinth of "deadlock unsecured souls" reveals a critical vulnerability in the heart of our digital world. From the classic contention between threads vying for shared resources to the subtle traps of asynchronous programming and the far-reaching implications for data integrity and automated systems, deadlocks represent a profound paralysis that can ensnare vital operations and compromise user trust. We've explored how a deadlock is a state of a system in which no single process/thread is capable of executing an action, and how this can cascade into significant problems.
Understanding the conditions that lead to deadlock—mutual exclusion, hold and wait, no preemption, and circular wait—is the first step towards prevention. By implementing strategies like strict resource ordering, robust timeout mechanisms, and careful architectural design, we can significantly reduce the likelihood of these digital stalemates. And when, inevitably, a deadlock does occur, having sophisticated detection mechanisms and recovery strategies, such as transaction rollbacks, is essential to minimize damage and restore system functionality. The protection of "unsecured souls"—be they data, processes, or the trust of those who rely on our systems—is not just a technical challenge but a continuous commitment to building resilient, reliable, and ethically sound digital environments. What are your experiences with deadlocks, and what strategies have you found most effective in protecting your digital "souls"? Share your insights in the comments below, or explore our other articles on system reliability and cybersecurity to deepen your understanding.
- Nastya Williams
- Emma Hiddleston
- Joe Piscopo Net Worth
- Skylar Blue Sextape
- Best Leaked Snapchat Nudes

Nerdly » ‘Deadlock’ Review
![Deadlock [Gameplay] - IGN](https://assets-prd.ignimgs.com/2024/08/29/deadlock-1724969546105.jpg)
Deadlock [Gameplay] - IGN
Introduction of Deadlock in Operating System - GeeksforGeeks
